
「ポケモンWordle」攻略のためにPythonで5文字のポケモンを探してみる
最近注目のブラウザゲームに「Wordle」というものがあります。5文字の単語から正解を探すゲームで、本家はニューヨーク・タイムズに買収され話題となりました。さまざまな派生作品も生まれており、その中にはポケモンの名前を当てる「ポケモンWordle」もあります。
「ポケモンWordle」を熱中してプレイしているうち、果たして5文字のポケモンってどれくらいいるのか、どの文字が最も多く使われているのかが気になりましたので、最近学習を進めているプログラミング言語「Python」を使って調べてみることにしました。
ポケモンWordleとは
5文字の好きなポケモンの名前を入力し、10回のうちにランダムに決定された答えのポケモンを当てるゲームです。
ポケモン名を入力するとヒントが現れます。例えば「イシツブテ」と入力すると…
![]()
![]()
すべてグレーでした。これは、答えのポケモンに「イ」「シ」「ツ」「ブ」「テ」のいずれの文字も入っていないことを意味します。次に「クレセリア」と入力すると…
![]()
今度は「リ」が黄色で表示されました。これは、位置は違っているけどどこかに入っていることを意味します。さらに「リザードン」と入力すると…
![]()
今度は「ン」が緑で表示されました。これは位置も合っていることを意味します。こんな感じで候補を絞りながら、答えのポケモンを見つけるゲームです。

無限に挑戦できる「エンドレス」、一定の条件がある「チャレンジ」、全ユーザー共通で一日一問同じポケモンが出題される「今日のお題」といった各モードが用意されています。
Pythonをすぐ使いたいならGoogle Colaboratoryがおすすめ
今回利用するのは「Google Colaboratory」というサービスです。よく「Google Colab」と略されます。ブラウザ上でpythonを実行できるサービスで、Googleアカウントさえあれば無料で使うことができます。
無料版では一定の制約があるものの、高性能なGPUを使えたり、主要なライブラリ(ツール集のようなもの)をインストールせず使えたりしますので、ローカル環境でpythonを行うよりずっと楽です。
Googleドライブとの連携もうれしいところ。今回もその手順で行っていますが、ドライブにファイルをアップロードしておけば、それを読み込んで利用することができます。
5文字のポケモンを探そう
事前準備
Google Colaboratoryはこちら。リンク先から「ファイル」→「ノートブックを新規作成」と進んでください。
それともうひとつ、ポケモンの全国図鑑番号と名前をまとめた表をcsv形式で用意しておきます。配布していいものかどうか分かりませんので掲載はしませんが、そんなに難しい作業ではありませんのでささっと作ってください。
なお、リージョン違いやフォルム違いのあるポケモンはひとつにまとめてあります。(例:ポワルン、ヤドン)
ドライブをマウント
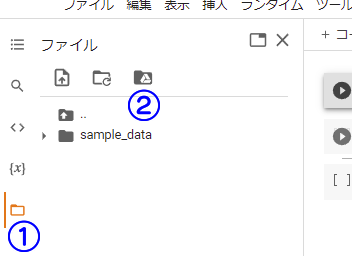
Googleドライブにアップロードしたデータを使うには、「マウント」という作業を行う必要があります。
左側のバーからフォルダアイコンを選択し、「ドライブをマウント」をクリックしましょう。
pandasを読み込む
ここからは、セルの中にコードを書いていきます。セルに書いたコードは、「Shift(Ctrl)+Enter」で実行できます。セル左端の再生ボタンでもOK。
まずライブラリを読み込みます。ライブラリとは、ざっくり言えばツール集のこと。簡単なコードを入力するだけで便利な機能が使えるようになります。
今回使うpandasは、表形式のデータの処理に優れたライブラリ。python版Excelと考えるのが分かりやすいかと思います。データ分析をするならほぼ必須です。
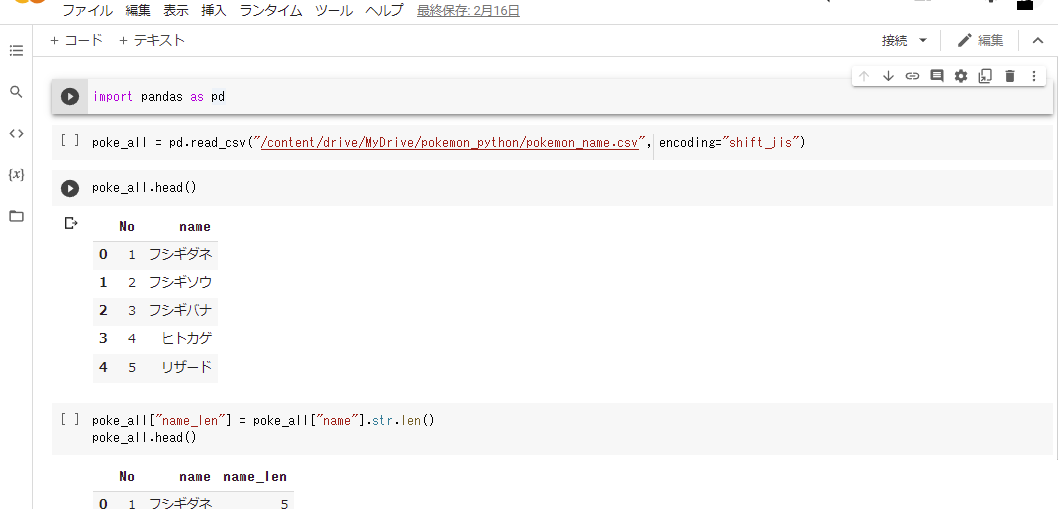
「import pandas」でpandasを読み込みます。「as pd」と付けることで、本来は「pandas」と書くべき場面で「pd」と省略できるようになります。
データを読み込む
Google Driveに保存した名前一覧表を読み込みます。今回は「poke_all」という名前(変数といいます)で読み込んでいます。ちなみに、「変数」と言っても入るのは数字だけではなく、文字列やリスト(複数データの集まり)なども入ります。
「pd.read_csv()」は、csvファイルを読み込む命令です。カッコの中に必要な情報を記述します。「" “」でファイルの場所(パス)を囲いましょう。Google Colabでは、ファイルを右クリックすると「パスをコピー」が表示されますので、そのままコピペしましょう。
「encoding="shift_jis"」は、文字コードを指定する部分です。なくてもうまくいく場合もありますが、日本語を含むデータはこれがないとおそらくうまくいきません。これでもだめな場合は、元データの文字コードを確かめて適切な文字コードを指定するか、文字コードを変換してから読み込みを試みてください。
データを確認する
データを読み込めたか確認するために、一部を表示してみましょう。このコードを実行すると、以下の表が出力されます。

「head()」は最初の5行を表示するコードです。新たに読み込んだり、変更を加えたりするたびにこうやって確認することで、ミスを減らすことができます。
「.」の後に実行する処理を書いていくパターンは今後もよく見かけることになりますので、ぜひ覚えておきましょう。
名前の文字数を表に追加する
poke_all.head()
ポケモンの名前の文字数を表に追加します。head()で表示しましょう。
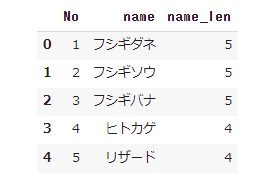
「poke_all[“name_len"]」は、「poke_allという表にname_lenという列を追加します」という意味です。
「=」に続く「poke_all[“name"].str.len()」は、「name列にある文字列の文字数を数えます」という意味です。
文字数ごとに集計する
文字数ごとに何匹のポケモンがいるか集計します。5文字が多いですね。2文字はピィだけか。
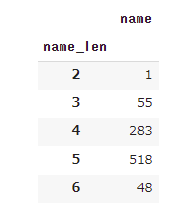
「poke_all[[“name", “name_len"]]」は、「poke_allという表のうち、name列とname_len列を見ますよ」という意味です。
「groupby(“name_len")」は、「name_lenの値でグループ分けしますよ」という意味です。今回であれば、文字数ごとにグループ分けをする処理になります。
「count()」は、「いくつあるか数えますよ」という意味です。これが「mean()」なら平均を出しますし、「max()」なら最大値を出します。
5文字のポケモンを抽出する
poke_name_five
Wordleで使うことが目的ですので、5文字のポケモンだけを抽出した表を作ります。「poke_name_five」と名付け、「=」の後に中身を指定します。(以下画像は最新作のネタバレ防止処理を施しています。)

「poke_all[poke_all[“name_len"] == 5]」は、「poke_allの表のうち、name_len列の値が5のもの」という意味になります。
ここで紛らわしいのが、「=」と「==」の違い。pythonでは「==」がイコール、「=」が代入の意味になります。数学とは使い方が異なりますので注意しましょう。
今回のコードであれば、「poke_name_fiveの中に、poke_allのname_len列が5のデータを入れる」となるわけです。
5文字ポケモンの表を保存する
表を保存します。最初に表の名前、「.」に続く「to_csv()」は、「csv形式で保存します」という意味。その後のカッコの中で、保存場所と文字コードを指定します。
読み込むときにはつけなかった「index=None」ですが、これを入れない場合は行番号を表す列が新たに挿入されます。今回は不要ですのでNoneと指定しておきます。
【終わりに】次回は文字検索
今回はここまで。次回はポケモンに多く使われている文字を、同じようにPythonで探していきたいと思います。
テキストや講座で配布された題材で学習をするのもいいですが、自分の好きな素材で取り組むと意欲がぐっと上がりますし、なにより応用力がつくのでおすすめです。
